目录
1. 基于检测的多目标跟踪策略
1.1 多目标跟踪任务模型
1.2 多目标跟踪算法 SORT
1.3 DeepSORT 算法
2 . 基于轨迹的学生行为分类模型
2.1 学生行为分类规则
2.2 实际场景分析
1. 基于检测的多目标跟踪策略
多目标跟踪任务涉及跟踪多个目标的身份信息关联,需要在相邻帧之间进行目标跟踪,与传统跟踪模型相比,这种任务的网络结构更为复杂。它必须同时处理目标轨迹的预测和目标内容的识别,以便有效匹配多个目标之间的数据。然而,在实际的多目标跟踪系统中,由于噪声的存在,跟踪算法的性能可能会受到影响,因此需要对跟踪算法进行改进以提高其性能。
在本部分,我们首先介绍了基于检测算法的多目标跟踪任务模型,以及我们所采用的DeepSORT V3多目标跟踪算法的工作流程和原理。
1.1 多目标跟踪任务模型
多目标跟踪任务的核心步骤主要包括检测、预测、匹配和更新四个关键阶段。在多目标跟踪中,首先需要利用检测器进行匹配和更新。该过程通常包括以下步骤:首先,读取视频中前后两帧,并将它们输入到检测器中,以便检测目标并输出检测结果。然后,对这些图像提取特征,包括外观和运动特征等。接下来,计算相邻两帧图像中目标的特征匹配程度,以确定物体的特征相似性。最后,为了将相同目标的数据进行关联,分配给这些关联目标一个唯一的身份ID。
在单目标识别中,通常只需要判断单一物体的识别,无需区分新目标和旧目标。然而,在多目标跟踪中,常常需要处理新目标的出现和旧目标的消失,这要求为每个目标分配一个唯一的身份ID,并在新旧物体出现和消失时相应地更新目标的ID。因此,与单目标跟踪相比,多目标跟踪更为复杂,其主要难点在于特征提取和数据关联。接下来,本文将分别介绍多目标跟踪中的两个关键问题:重识别和身份变换。
(1) 多目标跟踪与重识别
多目标跟踪的一个重要问题是重识别(Re-identification,ReID)。特别是在多个交叉摄像头的应用中,同一目标可能在不同摄像头中多次出现,每个摄像头都创建了一个独立的数据库。在这种情况下,重识别是解决多摄像头环境中多次出现目标的最有效方法。目前,ReID 技术已被广泛应用于解决行人重识别问题,对图像跨摄像头检索等应用场景具有高度有效性。例如,在图3.1中的示意图所示,它展示了如何将行人目标的图像与数据库中的行人特征进行匹配,以确定行人的身份。待检测图像通常是从不同摄像头拍摄的视频帧,经过网络预处理后,图像中保留了大多数相关信息,仅包括需要识别的行人信息和少量背景。
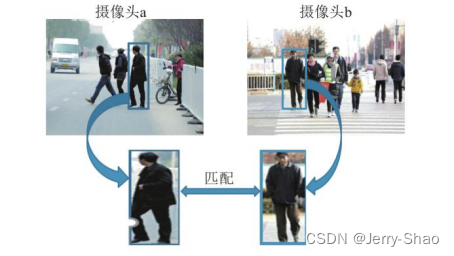
图 3.1 重识别示意图
(2) 多目标跟踪与身份变换
在多目标跟踪过程中,经常会出现同一目标的身份变换问题(ID-Switch)。为了确保轨迹跟踪的准确性,在一段视频中,每个跟踪目标通常只能分配一个唯一的身份ID。然而,当检测器输出的检测框与目标跟踪网络输出的预测框匹配出错时,往往会导致身份变换问题的出现。这种情况可能在目标长时间遮挡或互相交叉运动时发生,目标跟踪算法可能会错误匹配目标的ID,并将错误的匹配结果应用于后续帧的目标跟踪计算,从而严重影响了跟踪算法的准确性。
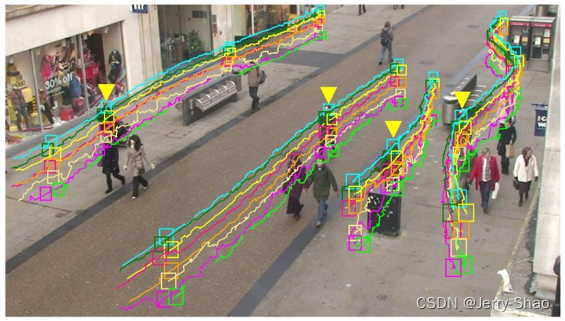
1.2 多目标跟踪算法 SORT
DeepSORT是一种计算机视觉目标跟踪算法,旨在为每个对象分配唯一的ID并持续跟踪。它是SORT算法的扩展和优化版本,旨在实现更高效和准确的跟踪。SORT是一种轻量级目标跟踪算法,用于处理实时视频流中的目标跟踪问题。DeepSORT引入了深度学习技术,以加强SORT的性能,并特别关注在多个帧之间跟踪目标的一致性。
跟踪算法的主要流程包括以下步骤:首先,它使用卡尔曼滤波(Kalman Filter)来预测目标的轨迹,然后使用匈牙利算法(Hungarian Algorithm)来对预测结果进行优化。值得一提的是,SORT算法采用在线跟踪的方式,不依赖未来帧的信息,同时具有最佳的模型性能(State of the Art,SOTA),并能够维持100帧每秒的帧速率。
(1)卡尔曼滤波
近年来,随着自动化技术的不断进步,对系统的鲁棒性提出了更高的要求。特别是在自动化操作系统中,如轨迹跟踪等动态系统,预测部分网络的性能好坏直接影响结果的准确率。在状态最优估计方法中,卡尔曼滤波是一种代表性的方法,在自动化操作系统中不可或缺。卡尔曼滤波具有容错能力,可以抑制系统参数和观测值的不准确噪声。此外,它还能够计算出动态方程状态值的最优估计。轨迹跟踪算法的核心思想是利用当前帧的目标特征信息来预测未来帧的动态信息,因此卡尔曼滤波在轨迹跟踪算法中扮演着关键角色。
卡尔曼滤波的数学模型如式(3.1)所示:

其中包括系统状态矩阵x、状态转移方程A、状态观测矩阵H、过程噪声w和实际测量状态矩阵观测量z。这些参数共同构成卡尔曼滤波的核心。为了增加卡尔曼滤波的容错性,噪声参数在实际应用中扮演重要角色。过程噪声和测量噪声用w和v表示,它们代表了系统参数和观测值中的不准确性和干扰。

卡尔曼滤波的状态预测和更新方程如式(3.3)和(3.4)所示:
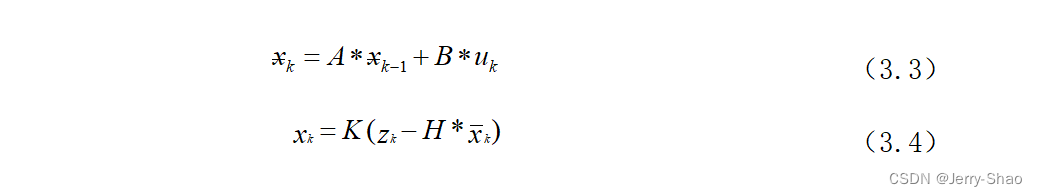
卡尔曼增益K在状态估计过程中用于调整预测误差和测量误差之间的权重,以使真实值x和估计值x尽可能接近。卡尔曼滤波可以提高状态估计的准确性,特别是在动态系统的轨迹跟踪中。
卡尔曼滤波的应用主要包括代价函数的计算和卡尔曼增益矩阵的计算。代价函数如式(3.5)所示:
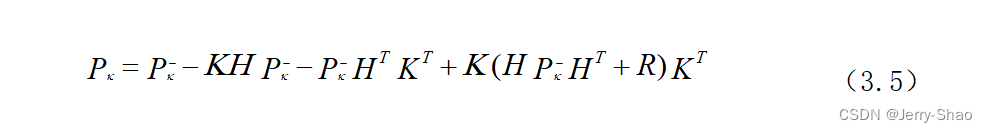
通过计算状态估计协方差Pk来得出。卡尔曼增益矩阵K由式(3.6)计算,估计误差方差矩阵Pk的计算如式(3.7),预测协方差矩阵Pk+1的计算如式(3.8)。卡尔曼滤波通过这些步骤来找到最优的预测值,提高了状态估计的准确性。
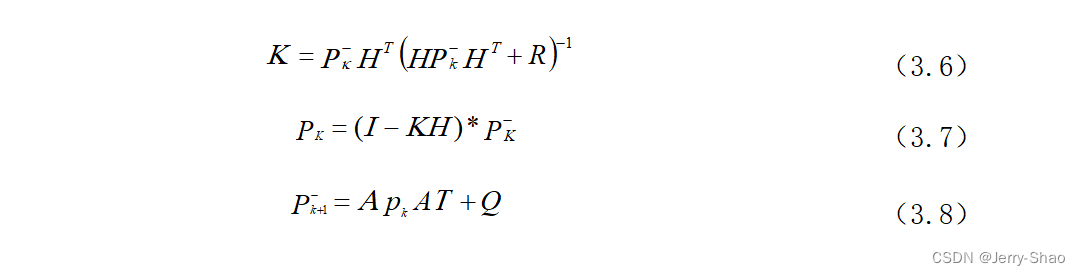
(2)匈牙利算法
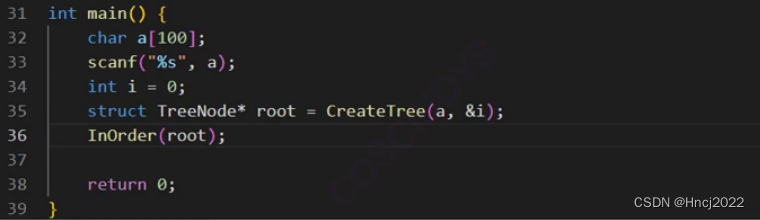
匈牙利算法是一种解决最优任务分配问题的经典算法,适用于在一组人员和任务之间找到最佳的分配方案,以使总成本最小化。为了解决这个问题,首先构建一个大小为n×n的矩阵,其中n代表人员和任务的数量。问题的目标是在这个矩阵中选择n个元素,以满足每一行和每一列都包含一个元素,并且使总成本最小。这个问题还规定了每个人只能执行一个任务,每个任务只能由一个人完成。具体的数学表达如下(见式3.9),其中代表效率矩阵中的元素。在效率矩阵中,每行和每列只能有一个元素的值小于其他元素,这表示了每个人完成特定任务的成本,以确保总成本最小。
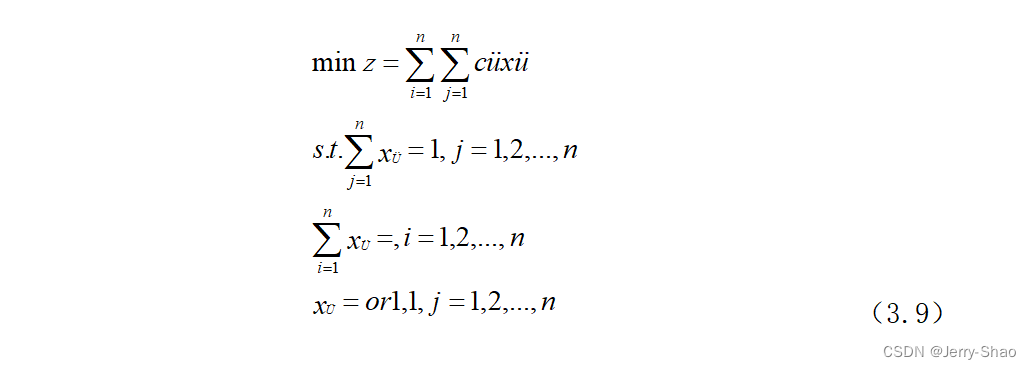
使用匈牙利算法有助于解决SORT目标跟踪算法中的结果分配问题,以找到检测框和跟踪框之间的最小成本,从而实现最佳任务分配。匈牙利算法基于对象重叠度(Intersection over Union,IoU)作为权重,SORT跟踪算法基于这些IoU权重来计算每一视频帧中跟踪目标之间的关联关系。同时,通过设置IoU的阈值来确保匹配和关联的准确性,可以消除无关的结果。此外,当目标被其他不相关的物体遮挡时,检测器可能会误识别目标,但如果障碍物的置信度略高于跟踪目标时,通过设置IoU可以减轻短期遮挡对目标跟踪的错误影响。然而,由于检测过程中存在大量检测框,它们的大小相差不大,计算它们之间的IoU值需要大量工作,可能无法获得理想的结果。这可能导致在遮挡期间目标跟踪的物体轨迹匹配失败。但当障碍物与目标的IoU超过设定的阈值并成功匹配时,当短期遮挡结束后,跟踪目标可以重新正确关联到其轨迹上。
在SORT(Simple Online and Realtime Tracking)工作时,首先运用卡尔曼滤波器来估计下一帧图像中每个目标的位置。然后,IoU(Intersection over Union)作为一种度量标准,根据每个检测器对下一帧图像中目标的识别来计算目标检测的准确度。这计算产生的IoU值被用作代价矩阵的一部分,以便在多目标跟踪问题中确定各个检测与预测目标之间的相关性。匈牙利算法被采用,以优化如何分配每个目标的轨迹,从而最大程度地提高跟踪的准确性和稳定性。
若检测框与预测框之间的IoU值低于预先设定的IoU阈值,这表示两者的重叠较小,被视为匹配失败,意味着该检测未与当前跟踪的目标相关联,需要考虑其他分配策略或者将其视为新的目标。这个阈值的设置对于跟踪算法的性能至关重要,因为它会影响分配的严格性和跟踪的鲁棒性。
(3)SORT 算法流程
SORT(Simple Online and Realtime Tracking)算法估计每个跟踪目标的身份ID并保持其不变。其状态建模包括质心坐标(u和v),尺寸参数(s和r),以及下一帧的预测状态(u,v,s,r)。卡尔曼滤波用于在匹配成功时将目标状态更新到结果集合中。
SORT的工作流程如下:首先,输入视频帧由检测器识别目标物体;然后,将检测结果传递给跟踪器以预测目标在下一帧图像中的位置;最后,将预测结果与检测结果进行比对,匹配成功的结果会被更新到卡尔曼滤波器中。由于跟踪器只能预测目标轨迹,无法识别下一帧图像中的目标信息,因此在多目标轨迹跟踪过程中,关联后续视频帧中的各个目标并识别它们是至关重要的一步。
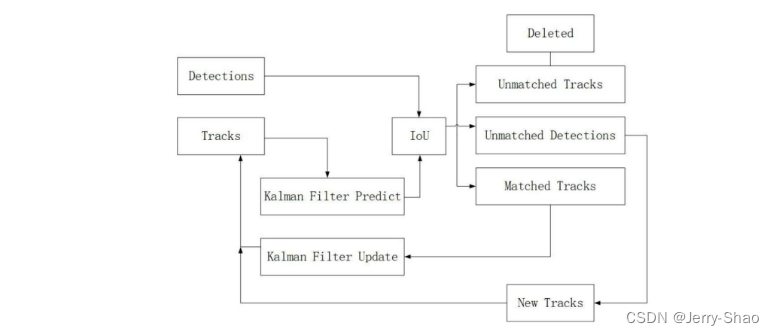
图3.3 SORT算法流程图
在这个情景中,“Detctions”指的是检测器输出的检测框信息,而“Tracks”则代表卡尔曼滤波器对下一帧图像中每个目标位置的预测信息。通过一个数据关联机制,系统进行目标轨迹的更新,同时计算检测框与预测框之间的交并比匹配。这个匹配过程有两种可能结果:首先是“Unmatched Tracks(Detections)”表示检测框未能成功匹配到预测框,如果这种连续匹配失败的情况超过了设定的次数,相关的身份 ID将被删除,被归为预测错误;其次是“Unmatched Detections”,这意味着在该帧图像中,跟踪目标对应的检测框未能成功匹配到相应的预测框。这种情况可能出现在画面中新出现了一个目标,而轨迹集合中没有可匹配的轨迹,此时算法会为新目标分配一个新的身份 ID。最后,还有“Matched Track”表示在该帧图像中,跟踪目标的检测框与预测框的交并比低于设定的阈值,匹配成功。
DeepSORT算法在SORT算法的基础上进行改进,引入物体的内容特征信息,降低了目标身份频繁切换的问题。DeepSORT算法通过计算前后帧目标之间的距离和物体特征的相似性,同时引入级联匹配策略和验证机制,以提高跟踪的准确性。
1.3 DeepSORT 算法
Deepsort行人跟踪算法架构DeepSort是一种基于深度学习的目标跟踪算法,它结合了深度学习和经典的Sort算法,用于在视频序列中进行多目标跟踪。DeepSort在Sort跟踪算法的基础上,引入级联匹配,优化了跟踪性能。DeepSort跟踪算法架构如图3.4所示。

图3.4DeepSort算法流程框架
主要步骤如下:①采用YOLOv8检测器检测出图像中的行人,获取到目标检测框。②将目标检测框与通过上一帧卡尔曼预测的预测框进行级联匹配。③将级联匹配中匹配失败的检测框和预测框再进行一次IOU匹配。④根据匹配的结果判断检测框和预测框是否符合条件。⑤更新目标的状态。
(1)级联匹配
级联匹配是DeepSort算法的核心部分,其流程如图3.5所示。
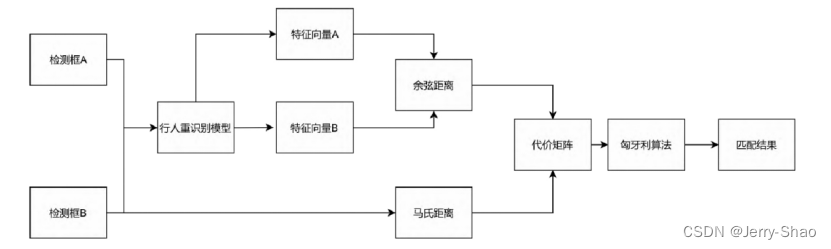
图3.5 级联匹配流程
首先根据YOLOv8模型检测出图像中的人物检测框A,通过卡尔曼滤波器对上一帧目标的运动轨迹进行预测,得到预测框B。然后将检测框A和预测框B输入到行人重识别网络,分别提取出行人检测框和预测框的特征向量A和特征向量B。计算出特征向量A和特征向量B之间的最小余弦距离矩阵,最小余弦距离计算公式为:
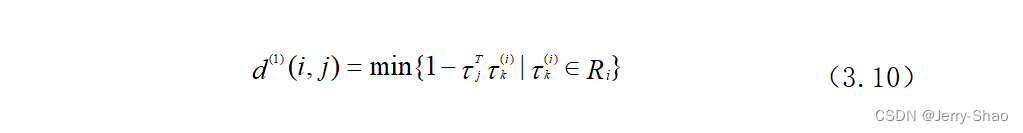
式中:是第j个检测框中的特征向量,
为跟踪器中存储的第i个特征向量。之后根据检测框A和检测框B计算出检测框之间的马氏距离(平方)矩阵:

式中:是一个数据点的特征向量,
是数据集的均值向量,
是数据集的协方差矩阵。最后根据最小余弦距离矩阵和马氏距离矩阵构建代价矩阵:
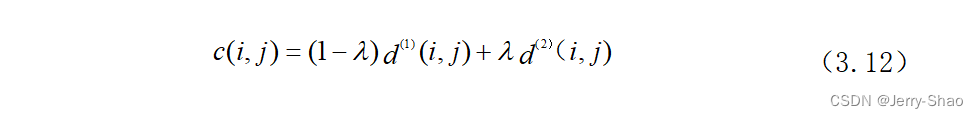
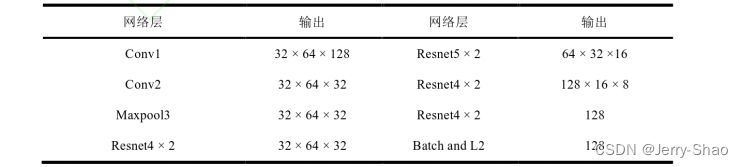
式中:λ是权重系数。代价矩阵用于表示每个检测到的人物框与预测的目标位置之间的匹配程度。最后根据代价矩阵通过识匈牙利算法进行最优匹配,从而关联每个检测到的人物框与其对应的预测目标。在级联匹配中,利用行人重别网络提取检测框和预测框的特征尤为重要,更为有效的特征提取可以改善级联匹配的结果,减少目标的匹配误差。传统的DeepSort算法中,提取特征的行人重识别网络为6维残差网络,其结构如表1所示,输入图像经过两层卷积后,经过6个残差块,再经过批处理和L2正则化输出128维度的特征向量,简称6维残差网络。
表3.1维残差网络每层输出特征尺寸
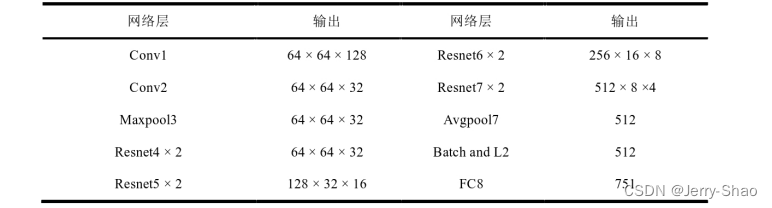
但是由于128维度的特征向量无法提取更深层次的特征,因此广泛用于传统DeepSort算法的重识别网络采用的是8维残差网络,其网络结构如表2所示,在8维残差网络[11]中,输入图像经过两个卷积层一个最大池化层,后面连接8个残差网络,最后经过平均池化层和批处理及L2正则化后输出512维度的特征向量。
表3.2维残差网络每层输出特征尺寸
2)改进DeepSort算法
余弦距离矩阵在DeepSort算法中对于人物在长期遮挡后恢复身份起着关键作用,改进的行人重识别网络可以同时输出灰度特征和融合后的特征,在此基础上利用此特性提出了一种新的余弦矩阵计算方法,新的余弦矩阵计算公式为:

式中:(i,j)为灰度分支所提取的特征向量所确定的余弦矩阵,
(i,j)为融合灰度特征网络提取的特征向量确定的余弦矩阵。k为比值,它是一个动态变化的值,通过每帧图像的饱和度来确定,即k等于饱和度。
图片的饱和度是色彩模型HSV的属性之一,饱和度的取值范围在0到1之间,饱和度越高,代表着图片色彩更加的鲜艳,较高的色彩饱和度说明图片中的彩色占据着主要成分,较低的饱和度说明灰色和白色占主要成分。图片的饱和度计算公式如下:
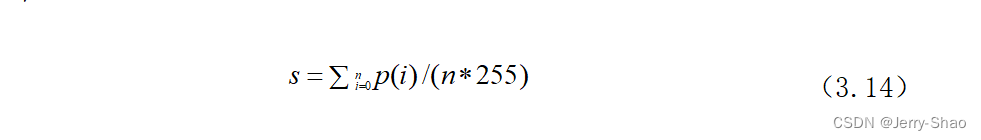
式中:为单个像素的饱和度,n为图片的像素点个数。当该帧图片的饱和度较低时,说明该帧图片以灰度色彩为主,k值较低,此时
(i,j)的值在确定余弦矩阵中的占比较低,
(i,j)的值在确定余弦矩阵中的占比较高,余弦矩阵主要以灰度特征来确定。当该帧图片的饱和度较高时,说明该帧图片以彩色为主,k值较高,此时
(i,j)的值在确定余弦矩阵中的占比较高,
(i,j)的值在确定余弦矩阵中的占比较低,余弦矩阵主要以融合后的特征来确定。
DeepSort则是一种基于深度学习的目标跟踪算法,通过对目标的特征进行编码和匹配,实现对目标在视频序列中的连续跟踪。将这两个算法结合在一起,可以实现对视频流中多个目标的实时跟踪与定位。
通过YOLOv8+DeepSort+PyQt+UI,用户不仅可以方便地进行目标跟踪,还能通过友好的界面设计进行更多的图像处理操作。他们可以选择不同的视频流进行实时跟踪,并在界面上观察到每个目标的位置、速度和轨迹等信息。用户也可以通过调整算法参数,优化目标跟踪结果并获得更准确的定位和匹配效果。
1. 卡尔曼滤波器对每个视频帧进行预测,生成预测轨迹边界框,并使用当前帧的检测器输出来进行数据关联。如果检测框匹配到前一帧中的卡尔曼滤波器输出的预测框,则将该检测框更新为新的轨迹跟踪结果,并继续预测下一帧的目标位置。
2. 如果卡尔曼预测框与检测框之间的匹配得分低于设定的阈值,即轨迹匹配失败,可能是因为新目标首次出现或因为某个检测物体长时间被其他目标遮挡。这将导致匹配失败,并为检测框分配一个新轨迹或删除匹配失败的预测轨迹。
3. 有时卡尔曼滤波器的预测框无法与任何检测框匹配成功,通常发生在目标超出图像边界的情况。对于再次匹配失败的预测框,算法会根据其状态和匹配失败次数来决定是否重复进行“预测-观测-更新”步骤或删除该轨迹。

图3.6 DeepSORT算法流程图
2 . 基于轨迹的学生行为分类模型
2.1 学生行为分类规则
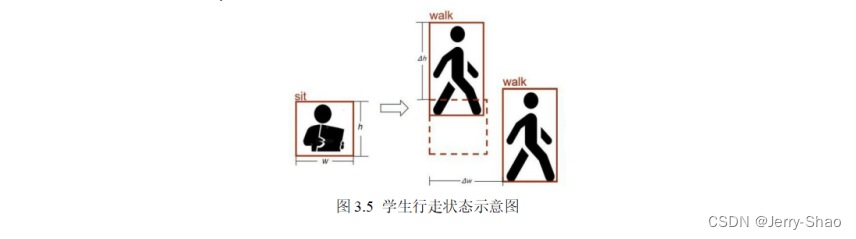
鉴于学生在教室内与摄像头的相对位置不一,以及他们的运动幅度不同,难以设定统一的参数。因此,本研究采用学生检测框的长宽(h,w)与座位坐标作为参考,通过监测质心坐标的变化(∆x,∆y),将学生的动态行为分为三个类别:“行走”,“站立”和“坐下”。
1. “行走”被定义为∆x或∆y坐标的移动范围大于h或w,如图3.5所示。
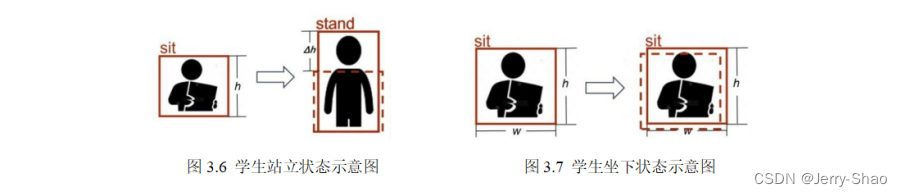
2. “站立”被定义为∆x坐标不变,∆y坐标减少大于1/2h但小于h,如图3.6所示。
“坐下”被定义为∆x和∆y坐标都在1/2(h,w)范围内活动,如图3.7所示。
2.2 实际场景分析
在教师进行课堂授课时,大多数学生通常坐着聆听。然而,互动式教学方法,如提问、鼓励学生上前回答问题或在黑板上解答问题,可以极大地激发学生的求知欲,促进他们的思维发展,从而提高教学质量和效果。
在图3.8中,显示了学生正常聆听课堂时的状态。而在图3.9的左上角,一个学生站起来回答问题。通过比较其检测框的位置与原始座位,发现∆h坐标减少了大于1/2h但小于h,因此被判定为“站立”。在图3.10中的左上角,一个学生离开座位并走向讲台周围。通过比较其检测框的∆w和∆h坐标的移动范围,发现其值大于h或w,因此被判定为“行走”。至于其他学生,其检测框的∆w和∆h坐标都在1/2(h,w)内,因此被判定为“坐下”状态。

物体框的数量;为第i个物体框的坐标;
为第i个物体的真实标注框的坐标;
为权重值;IoU(
,
)为第i个物体框与真实标注框之间的IoU值。
结合上述2个损失后得到的最终回归损失为:
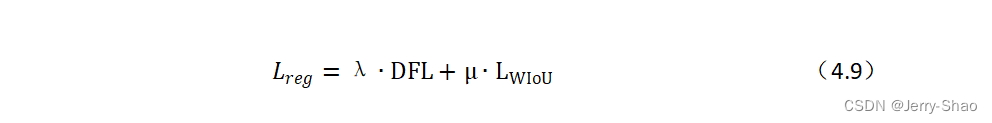
权重系数λ和μ的确定参考了YOLOv8的回归损失权重设置。高IoU值对于目标的准确定位和检测非常重要,因此需要较大权重;DFL在模型训练中容易导致过拟合问题,从而影响模型的泛化能力,因此需要较小权重。因此,通过相关实验分析,取λ=1/6,μ=5/6。结合后的回归损失使得模型的训练效率得到提升。
本文以实现高效课堂远程监控为背景,主要利用YOLOv8模型基于深度学习进行学生课堂行为识别技术的研究。首先确认了学生课堂行为识别的基本概念与关键技术,介绍了不同技术下的学生课堂行为识别算法类型。然后,在实验部分,通过OpenCV采集了图像,利用LabelImg工具进行数据标注,通过Anaconda搭建实验所需环境,并在Pycharm平台运行代码,最后通过最新的YOLOv8实现对可用于学生课堂行为识别模型的训练与测试。
如图4.9所示。通过对行为数据进行适当的处理和计算机分析,实现对学生课堂行为的捕捉和识别。
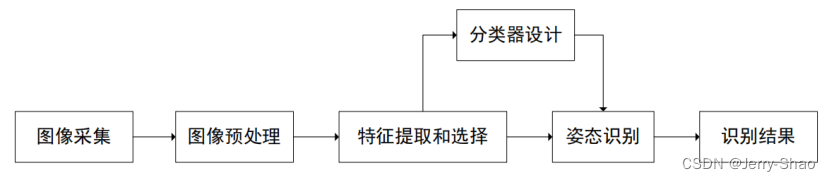
图4.9 基于视觉的姿态识别的关键技术